Sense and Nonsense of Unit Test Coverage
Unit testing is certainly one of the best known and most effective methods of software testing. Unit tests are written parallel to software development (at least they should be). Accordingly, errors can be detected at an early stage and may even be narrowed down to the line in the code that caused them. By consistently writing and repeating unit tests, time-consuming debugging sessions can be saved. Of course, this also applies to code reviews. The advantage of unit tests, however, is that they can be automated. Errors resulting from code changes are automatically detected the next time the build server is run. A further advantage of this is isolating lines of code from the rest of the system and allowing them to be tested under all conceivable preconditions. Thus, special cases can be considered which occur very rarely under normal conditions.
With all the advantages one should think that every additional line I test increases the probability to find an error …
What does coverage actually mean?
At the beginning some theory: Coverage refers to the degree to which a software is covered by tests. This value is usually given as a percentage. There are different ways to calculate coverage. Two of the most common coverage metrics are:
- Statement Coverage: Percentage of statements covered.
- Branch Coverage: Percentage of the branches that were run through during the test.
The figure below shows an example of coverage calculation. The image shows the result of the test coverage of the function “testFunction”. If a line of code has been run through in at least one test, it is highlighted in green. If the line is not run in any test, it is displayed in red.
Relative to the first if-else statement (lines 14 to 19), the statement coverage is 100 % because all statements have been run through (the else-branch does not contain any statements). The branch coverage for the same lines is only 50 %. Finally, the else-condition is not run through in any test.
The second if-else statement (lines 21-26) results in a branch and statement coverage of 50% each, since the else-branch that has not been run through contains an instruction here.
Apart from the two metrics, there are other methods to calculate test coverage (function-coverage, modified condition/decision coverage, …).
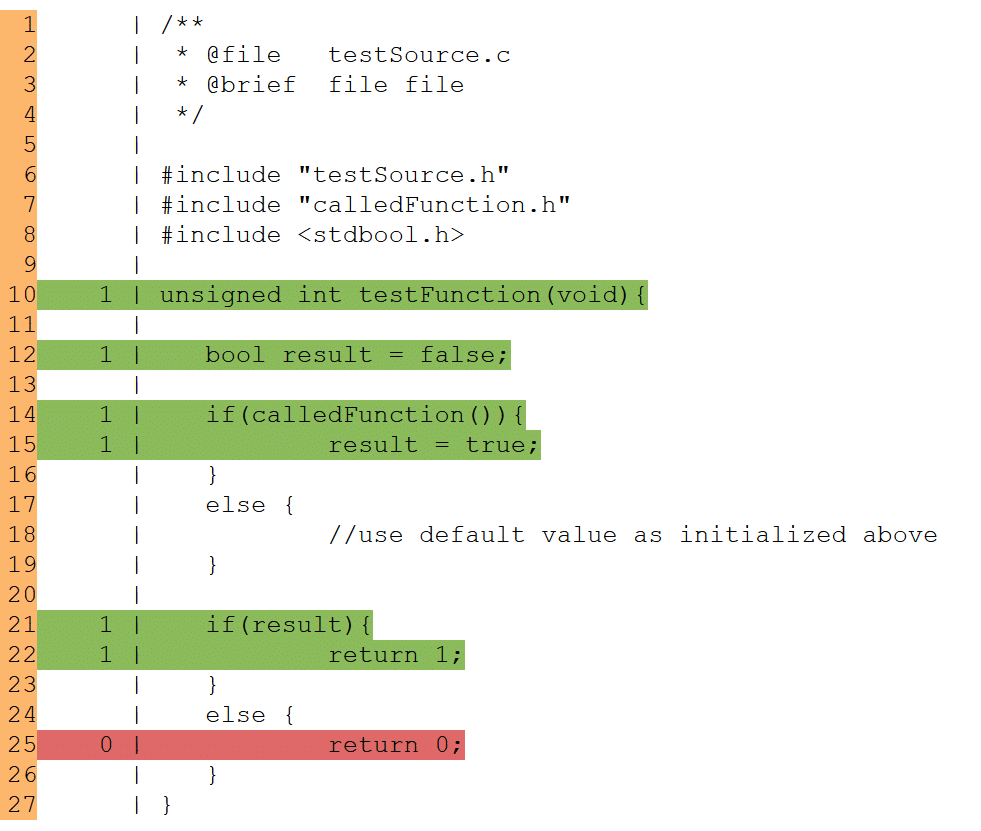
Test coverage of the “testFunction” function
The problem with coverage
Some time ago I was working on a project where the customer’s processes required 100% statement coverage. Many well-known developers to whom I told about these requirements were shocked. This approach is common for some companies in safety-critical areas (such as medical technology). In my opinion, however, this makes only limited sense for the following reasons:
When planning projects, far too little time is often allowed for software testing. The reason for this probably fills another blog entry. However, the consequences should be clear. If the development processes prescribe a certain minimum coverage – possibly even 100% – this means a lot of work for the developers in any case (don’t forget that in case of code changes the unit tests already written may have to be adapted or even completely rewritten as well). If this effort is not included in the plan, the developer will hardly be able to conscientiously do this huge amount of work. At this point, let’s assume that the developer is testing his code himself. This may not be advisable, but it is common practice.
Fortunately, the processes here usually provide a direct alternative! As a rule, a test coverage of only x % is prescribed, but the way to achieve this is not. If we were in an ideal world, the developer would of course still devote himself conscientiously to every single unit test in order to obtain the highest possible detection probability for errors; even if only dull and completely linear getter functions are to be tested. In reality, however, there is often no time for this, or the developer has become so dulled by writing completely nonsensical tests that he begins to feel that unit testing itself is an extremely unnecessary duty. Thus, the demand for a high test coverage can possibly even worsen the quality of the individual tests. Anyone who has ever written unit tests knows that it is easy to pass them when completely meaningless conditions (e.g. “3 = 3”) are met. This example is of course exaggerated, but shows that the results of unit tests do not necessarily have to be meaningful. In the end, usually no one asks what the individual tests actually test. Especially not if the automatically generated protocol spits out a high test coverage and it is even highlighted in green!
The correlation between coverage and errors
A high test coverage alone is therefore not necessarily a measure of how many errors can be expected in software. A study carried out by the University of Gothenburg in collaboration with Ericsson comes to a similar conclusion. The paper entitled “Mythical Unit Test Coverage”¹ describes a study that looks for a correlation between unit test coverage and errors found in the code. A clear correlation to the test coverage could not be found, but to the complexity and size (lines of code) of the software files, as well as to the number of changes made. It therefore seems to be much more effective to invest time in readable, encapsulated code, compliance with coding guidelines, or the design of a clear and maintainable software architecture, rather than excessive unit testing to drive up coverage metrics.
Why do coverage software metrics still hold up?
In principle, this question is easy to answer. The meaningfulness of tests can only be evaluated if the source code is dealt with intensively. Of course, this is quite time-consuming. On the other hand, it is much easier to compare a number in a protocol with the target value, which can even be done automatically. If an error then occurs in the field, you can refer to the protocol with the note: “We have tested our software to the best of our knowledge! Accordingly, it was impossible for us to expect that it would still contain errors”. This of course ensures a certain degree of security. In the best case, the forced test coverage even achieves a certain “minimum standard”. Of course, error-free code cannot be achieved with this.
What you can do better
It’s getting a little harder here. The following measures already mentioned are important building blocks for a (preferably) error-free code:
- A code complexity as low as possible.
- A sensible encapsulation of software and the prevention of oversized software files. Only if code is clear an effective code reviews can be carried out.
- A clear and well thought-out software architecture that can also be adhered to by the developer (and whose adherence is of course checked with the help of code reviews).
Nevertheless, unit tests, from the advantages described at the beginning and of course completely undisputed, should not be renounced. However, my suggestion would be to work out a concept for a project (or better for all software projects in a company) and to define what should be tested at all. This can be done, for example, via a checklist:
Does the function implement risk measures? ⇾ test
Could the function lead to damage to the user in the event of a malfunction? ⇾ test
In the context of a code review, which is mandatory anyway for security-critical software, a developer who has NOT written the code then checks whether every function that falls into the grid is also covered by a corresponding unit test. This enables the developer to focus on the essentials. In order to increase the quality of the unit tests, one can additionally carry out random reviews of the unit tests. If many problems are found, the search grid is extended. If this process is carried out regularly, experience shows that developers start writing better tests all by themselves.
In order to further improve the quality of unit testing, it may make sense to use external forces for software testing. For example, this could be a developer from another department who usually does not work with the author of the code. If no such developer is available in the company, it may also be useful to hire an external service provider. Such an external tester has the following advantages, among others:
- The tester does not know the developer personally and can therefore handle code and unit tests with a certain neutrality.
- The tester sees software architecture and coding guidelines for the first time and has not yet become accustomed to them if certain deviations have become commonplace in the developer group.
- An in-project developer who checks someone else’s code or writes unit tests for someone else might be afraid of uncovering too many bugs that make him “pedantic”. This, in turn, could lead to the author taking revenge next time and taking the tester’s code apart just as critically. Of course, an external tester does not have this problem.
- An external developer as a tester, who otherwise does not work with the developers, automatically compares development processes and the developed software with the processes and code from other projects. In this way he may find weaknesses that the project-internal developers overlook.
Bottom line
Unit tests are definitely an important pillar in software testing for early and targeted detection of possible errors. If the unit test is combined with other tools such as code reviews (in my opinion the most effective tool) and static code analysis in a mature test concept, the quality of your software can be significantly improved. However, a high unit test coverage alone says little about the existing errors in a software. If you rely exclusively on high test coverage in your test concept, the quality of the individual tests (and thus of the software itself) may even deteriorate under certain circumstances. It is much more important to develop a good test concept and to determine who has to test what and who checks this. A (project-)external software tester is always an enrichment. The best recipe for high quality code is a good software architecture that is translated into readable and not unnecessarily complex software modules.
Note:

Bjoern Schmitz
After studying medical technology, Bjoern Schmitz first moved into research, where he dealt with the development of hardware and firmware in the fields of medical sensor technology, as well as the processing and analysis of biosignals. Since July 2017, Mr. Schmitz has been a member of the MEDtech engineering team and works mainly as a firmware developer.