Sinn und Unsinn der Unittest Coverage
Unittests gehören sicher zu den bekanntesten und wirksamsten Methoden des Softwaretests. Unittests werden parallel zur Softwareentwicklung geschrieben (sollten sie zumindest). Dementsprechend können Fehler frühzeitig erkannt und unter Umständen sogar direkt bis auf die verursachende Zeile im Code eingegrenzt werden. Durch konsequentes Schreiben und Wiederholen von Unittests lassen sich zeitaufwendige Debugging-Sessions ersparen. Natürlich gilt dies auch für Code Reviews. Der Vorteil von Unittests liegt allerdings in ihrer Automatisierbarkeit. So werden Fehler, die sich durch Codeänderungen ergeben, ganz automatisch beim nächsten Lauf des Buildservers erkannt. Ein weiterer Vorteil dieser liegt darin, dass sich Codezeilen vom restlichen System isolieren und unter allen denkbaren Vorbedingungen testen lassen. So können gezielt Sonderfälle betrachtet werden, welche unter normalen Bedingungen nur sehr selten auftreten.
Bei all den Vorteilen sollte man also denken, dass jede zusätzliche Zeile, die ich teste, die Wahrscheinlichkeit erhöht, einen Fehler zu finden …
Was bedeutet eigentlich Coverage?
Zu Beginn etwas Theorie: Die Coverage (zu Deutsch Abdeckung bzw. Testabdeckung) bezeichnet den Grad, zu dem eine Software durch Tests abgedeckt wird. Dieser Wert wird – in der Regel – in Prozent angegeben. Es gibt verschiedenen Wege Coverage zu berechnen. Zwei der gängigsten Coverage-Metriken sind:
- Statement-Coverage: Anteil an abgedeckten Statements.
- Branch-Coverage: Anteil der Verzweigungen, welche beim Test durchlaufen wurden.
Die Abbildung unten zeigt ein Beispiel für Coverage-Berechnung. Das Bild zeigt das Ergebnis der Testabdeckung der Funktion „testFunction“. Wurde eine Codezeile bei mindestens einem Test durchlaufen, wird diese grün hinterlegt. Wird die Zeile bei keinem Test durchlaufen, wird diese rot dargestellt.
Bezogen auf die erste if-else-Anweisung (Zeile 14 bis 19) ergibt sich ein Statement-Coverage von 100 % da sämtliche Statements durchlaufen wurden (der else-branch enthält keinerlei Statements). Die Branch-Coverage hingegen für dieselben Zeilen liegt bei lediglich 50 %. Schließlich wird die else-Bedingung bei keinem Test durchlaufen.
Bei der zweiten if-else-Anweisung (Zeile 21-26) ergibt sich eine Branch- und Statement-Coverage von jeweils 50 %, da der nicht durchlaufene else-branch hier eine Anweisung beinhaltet.
Abgesehen von den beiden Metriken gibt es noch weitere Methoden, um Testabdeckung zu berechnen (function-coverage, modified condition/decision coverage, …).
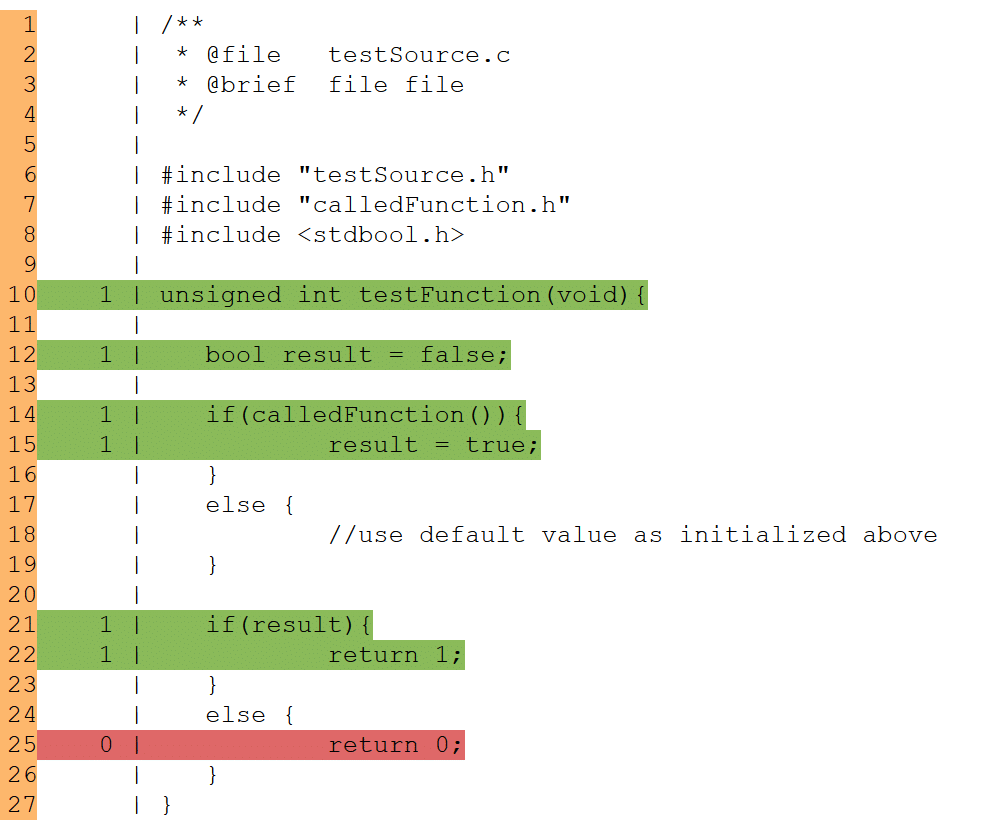
Testabdeckung der Funktion „testFunction“
Das Problem mit der Coverage
Ich habe vor einiger Zeit an einem Projekt gearbeitet, in dem die Prozesse des Kunden 100 % Statement-Coverage forderten. Viele bekannte Entwickler, denen ich von diesen Vorgaben erzählte, reagierten geradezu schockiert. Dabei ist dieses Vorgehen bei einigen Unternehmen in sicherheitskritischen Bereichen (wie zum Beispiel der Medizintechnik) üblich. Meiner Meinung nach macht dies allerdings aus den folgenden Gründen nur begrenzt Sinn:
Bei der Planung von Projekten wird häufig viel zu wenig Zeit für den Softwaretest eingeplant. Die Begründung hierfür füllt vermutlich einen weiteren Blogeintrag. Die Konsequenzen sollten allerdings klar sein. Wenn die Entwicklungsprozesse eine gewisse Mindest-Coverage vorschreiben – eventuell sogar 100 % – bedeutet dies in jedem Fall jede Menge Arbeit für die Entwickler (man darf nicht vergessen, dass bei Codeänderungen die bereits geschriebenen Unittests unter Umständen ebenfalls angepasst oder sogar völlig neu geschrieben werden müssen). Ist dieser Aufwand nicht eingeplant, wird es der Entwickler kaum schaffen, diesen gewaltigen Berg an Arbeit gewissenhaft zu erledigen. An dieser Stelle nehmen wir einfach mal an, der Entwickler testet seinen Code selbst. Das ist zwar nicht unbedingt ratsam, trotzdem aber gängige Praxis.
Glücklicherweise liefern die Prozesse hier meistens auch direkt einen Ausweg! In der Regel wird lediglich eine Testabdeckung von x % vorgeschrieben, allerdings nicht wie diese erreicht werden soll. Würden wir uns in einer idealen Welt befinden, würde sich der Entwickler natürlich trotzdem gewissenhaft jedem einzelnen Unittest widmen, um aus diesem eine möglichst hohe Entdeckungswahrscheinlichkeit für Fehler zu erhalten; selbst dann, wenn nur öde und völlig linear verlaufende Getter-Funktionen getestet werden sollen. In der Realität bleibt aber dafür oft gar keine Zeit oder der Entwickler ist durch das Schreiben von völlig unsinnigen Tests so weit abgestumpft, dass er anfängt, Unittests an sich als äußerst unnötige Pflicht zu empfinden. So kann die Forderung nach einer hohen Testabdeckung unter Umständen sogar die Qualität der einzelnen Tests verschlechtern. Jeder, der schon einmal Unittests geschrieben hat weiß, dass es ein leichtes ist, diese als „bestanden“ zu werten, wenn völlig sinnlose Bedingungen (Beispielsweise „3 = 3“) erfüllt werden. Dieses Beispiel ist natürlich stark übertrieben, zeigt aber, dass die Ergebnisse von Unittests nicht zwangsweise aussagekräftig seien müssen. Am Ende fragt in der Regel niemand mehr danach, was die einzelnen Tests eigentlich genau testen. Vor allem dann nicht, wenn das automatisch generierte Protokoll eine hohe Testabdeckung ausspuckt und diese dann sogar noch mit grüner Farbe hinterlegt ist!
Die Korrelation zwischen Coverage und Fehlern
Eine hohe Testabdeckung allein ist also nicht zwingend ein Maß dafür, wie wenig Fehler in einer Software zu erwarten sind. Eine Arbeit der Universität Göteborg, die in Zusammenarbeit mit Ericsson erstellt wurde, kommt zu einem ähnlichen Ergebnis. Die Arbeit unter dem Titel „Mythical Unit Test Coverage“¹ beschreibt eine Studie, bei der nach einer Korrelation zwischen Unittest-Coverage und im Code gefundenen Fehlern gesucht wird. Eine klare Korrelation zur Testabdeckung konnte dabei zwar nicht gefunden werden, wohl aber zur Komplexität und Größe (lines of code) der Softwaredateien, sowie zur Anzahl der vorgenommenen Änderungen. Es scheint demnach deutlich wirksamer zu sein, Zeit in gut lesbaren, gekapselten Code, die Einhaltung von Kodierrichtlinien oder den Entwurf einer klaren und einhaltbaren Softwarearchitektur zu investieren, anstatt in exzessives Unittesting, um die Coverage-Metrik hochzutreiben.
Warum halten sich Coverage-Softwaremetriken trotzdem?
Diese Frage lässt sich im Prinzip einfach beantworten. Die Sinnhaftigkeit von Tests lässt sich nur bewerten, wenn man sich sehr intensiv mit dem Source-Code auseinandersetzt. Das ist natürlich ziemlich aufwendig. Hingegen ist es deutlich einfacher, eine Zahl in einem Protokoll gegen den Sollwert abzugleichen, was zudem sogar automatisiert ablaufen kann. Tritt dann ein Fehler im Feld auf, kann auf das Protokoll mit dem Hinweis: „Wir haben unsere Software nach bestem Wissen und Gewissen getestet! Dementsprechend konnten wir unmöglich damit rechnen, dass diese trotzdem Fehler enthält“ verwiesen werden. Das sichert einen natürlich in gewissem Maße ab. Im besten Fall erreicht man mit der erzwungenen Testabdeckung sogar einen gewissen „Minimalstandard“. Fehlerfreien Code erreicht man hiermit aber natürlich nicht.
Was man besser machen kann
Hier wird es schon etwas schwieriger. Folgende bereits angesprochene Maßnahmen sind wichtige Bausteine zu einem (möglichst) fehlerfreien Code:
- Eine möglichst geringe Code-Komplexität.
- Eine sinnvolle Kapselung von Software und das Verhindern von überdimensional großen Softwaredateien. Nur wenn Code übersichtlich ist, lassen sich effektive Code Reviews durchführen.
- Eine klare und gut durchdachte Softwarearchitektur, die auch vom Entwickler eingehalten werden kann (und deren Einhaltung selbstverständlich mithilfe von Code Reviews überprüft wird).
Trotzdem sollte auf Unittests, aus den eingangs beschrieben und selbstverständlich völlig unstrittigen Vorteilen, nicht verzichtet werden. Mein Vorschlag wäre allerdings für ein Projekt (oder besser für alle Softwareprojekte in einem Unternehmen) ein Konzept zu erarbeiten und darin zu definieren, was überhaupt getestet werden sollte. Das kann zum Beispiel über eine Checkliste geschehen:
Implementiert die Funktion Risikomaßnahmen? ⇾ testen
Könnte die Funktion bei einem Fehlverhalten zu einem Schaden des Anwenders führen? ⇾ testen
Im Rahmen eines Code Reviews, welches bei sicherheitskritischer Software ohnehin Pflicht ist, überprüft dann ein Entwickler, der den Code NICHT geschrieben hat, ob jede Funktion, die ins Raster fällt, auch durch einen entsprechenden Unittest abgedeckt wird. Hiermit wird dem Entwickler ermöglicht, sich auf das wesentliche zu fokussieren. Um die Qualität der Unittests zu erhöhen, kann man zusätzlich stichprobenartige Reviews der Unittests durchführen. Werden dabei viele Probleme gefunden, wird das Suchraster erweitert. Wenn dieser Prozess regelmäßig durchgeführt wird, dann zeigt die Erfahrung, dass Entwickler ganz von allein anfangen, bessere Tests zu schreiben.
Um die Qualität der Unittests weiter zu erhöhen, kann es Sinn ergeben, externe Kräfte für den Softwaretest hinzuzuziehen. Das kann z. B. ein Entwickler aus einer anderen Abteilung sein, der in der Regel nicht mit dem Autor des Codes zusammenarbeitet. Falls kein entsprechender Entwickler im Unternehmen verfügbar ist, kann es auch sinnvoll sein, einen externen Dienstleister zu beauftragen. Solch ein externer Tester hat unter anderem folgende Vorteile:
- Der Tester kennt den Entwickler nicht persönlich und kann Code und Unittests daher mit einer gewissen Neutralität begegnen.
- Der Tester sieht Softwarearchitektur und Kodierrichtlinien zum ersten Mal und hat sich noch nicht daran gewöhnt, wenn sich gewisse Abweichungen in der Entwicklergruppe eingebürgert haben.
- Ein projektinterner Entwickler, der den Code eines anderen überprüft oder Unit-Tests für diesen schreibt, könnte sich davor fürchten, zu viele Fehler aufzudecken, die ihn „pedantisch“ erscheinen lassen. Denn dies könnte wiederum dazu führen, dass der Autor sich das nächste Mal rächt und den Code des Testers ebenso kritisch auseinander nimmt. Ein externer Tester hat dieses Problem natürlich nicht.
- Ein externer Entwickler als Tester, der sonst nicht mit den Entwicklern zusammenarbeitet, vergleicht automatisch Entwicklungsprozesse und die entwickelte Software mit den Prozessen und dem Code aus anderen Projekten. So findet er eventuell Schwachstellen, welche die projektinternen Entwickler übersehen.
Fazit
Unittests sind definitiv eine wichtige Säule im Softwaretest, um mögliche Fehler frühzeitig und zielgerichtet aufzudecken. Bindet man den Unittest zusammen mit anderen Werkzeugen wie Code Reviews (aus meiner Sicht das wirkungsvollste Werkzeug) und der statischen Codeanalyse in einem ausgereiften Testkonzept ein, kann man die Qualität seiner Software deutlich erhöhen. Eine hohe Unittest-Abdeckung allein sagt allerdings wenig über die vorhandenen Fehler in einer Software aus. Setzt man bei seinem Testkonzept ausschließlich auf hohe Testabdeckung, kann sich unter Umständen sogar die Qualität der einzelnen Tests (und damit der Software an sich) verschlechtern. Viel wichtiger ist es ein gutes Testkonzept zu entwickeln und festzulegen, wer was zu testen hat und wer dies überprüft. Ein (Projekt-)externer Softwaretester ist dabei immer eine Bereicherung. Es bleibt jedoch dabei: Das beste Rezept für Code mit hoher Qualität ist eine gute Softwarearchitektur, die in lesbare und nicht unnötig komplexe Softwaremodule übersetzt wird.
Hinweise:
Interessieren Sie sich für weitere Tipps aus der Praxis? Testen Sie unseren wöchentlichen Newsletter mit interessanten Beiträgen, Downloads, Empfehlungen und aktuellem Wissen.
Björn Schmitz und seine Kollegen bloggen regelmäßig über Softwareentwicklung unter https://medtech-ingenieur.de/blog/.

Björn Schmitz
Nach seinem Studium der Medizintechnik verschlug es Björn Schmitz zunächst in die Forschung, wo er sich mit der Entwicklung von Hardware und Firmware in den Bereichen medizinische Sensorik, sowie der Verarbeitung und Analyse von Biosignalen beschäftigte. Seit Juli 2017 gehört Herr Schmitz zum MEDtech-Ingenieur Team und ist hier vor allem als Firmwareentwickler tätig.